Following the release of OpenAI’s open-source model gpt-oss, I set out to benchmark its performance in conjunction with PostgreSQL, focusing specifically on integration with pgAssistant. All evaluations were conducted locally on a MacBook Pro M4 Pro (24 GB RAM), using Ollama as the model runtime environment.
gpt-oss installation
To install this new model, first download the latest version of ollama, then run this :
ollama pull gpt-oss:20b
Ollama should now serve the API at: http://localhost:11434
pgAssistant configuration
In a Docker environment, use the following docker-compose.yml file :
services:
pgassistant:
image: bertrand73/pgassistant:1.9.7
restart: always
environment:
- OPENAI_API_KEY=nothing
- LOCAL_LLM_URI=http://host.docker.internal:11434/v1/
- OPENAI_API_MODEL=gpt-oss:20b
- SECRET_KEY=bertrand
ports:
- "8081:5005"
You can also configure the LLM settings in pgAssistant via the “LLM Settings” menu:
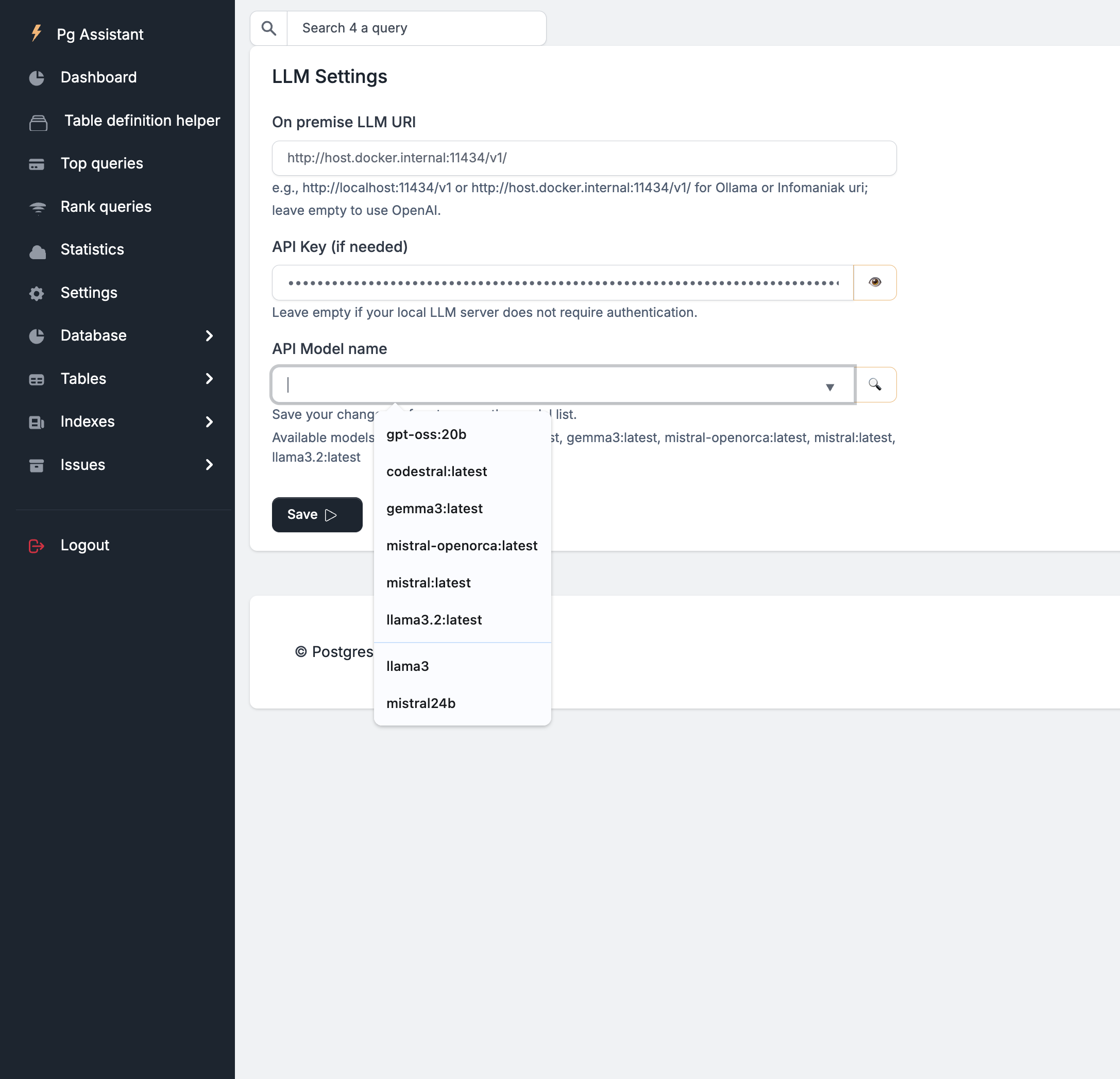
Test
Let’s use the pgAssistant table definition helper to see how gpt-oss performs:
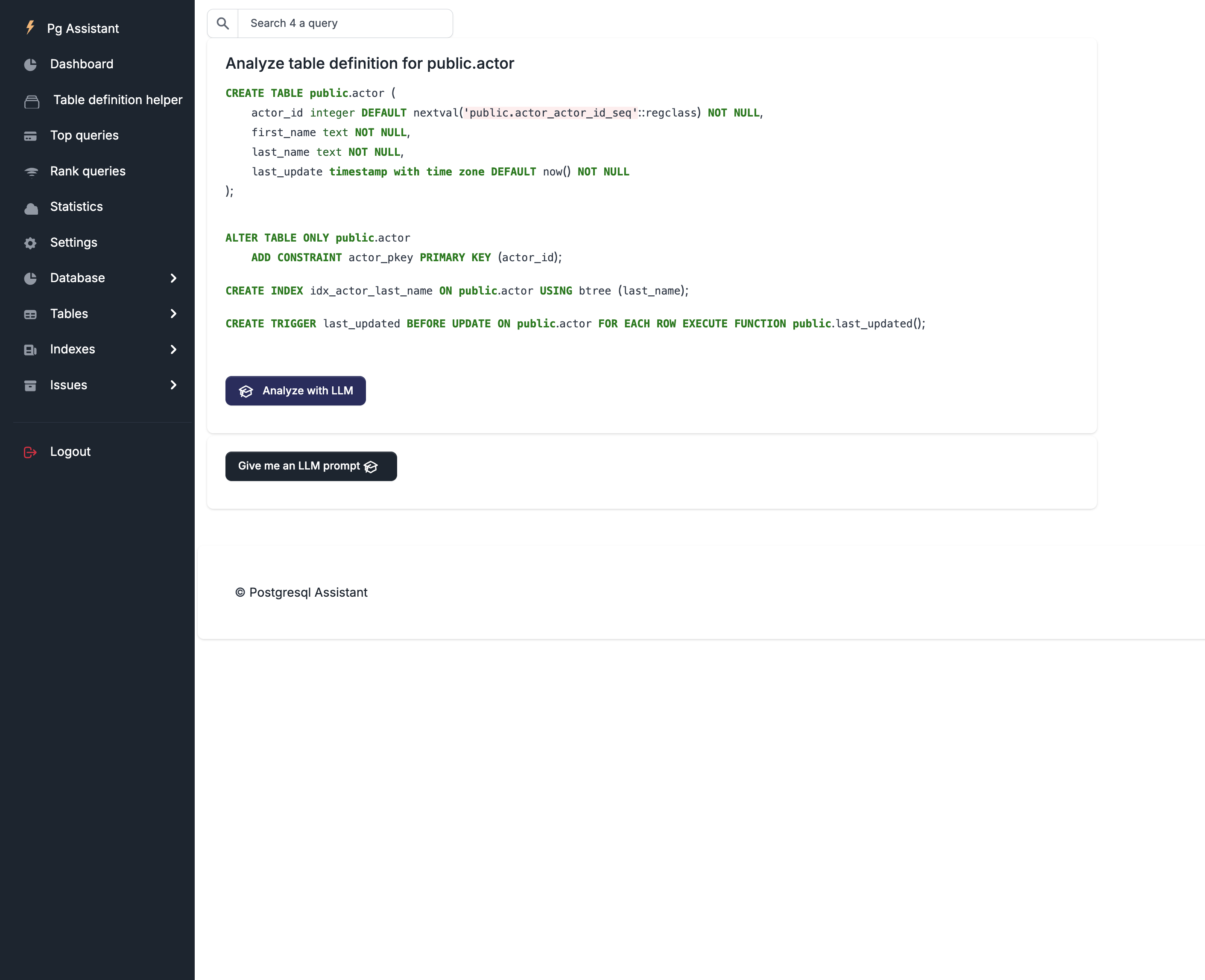
Click on the “Analyze with LLM” button.
After less than 40 seconds, here are the results :
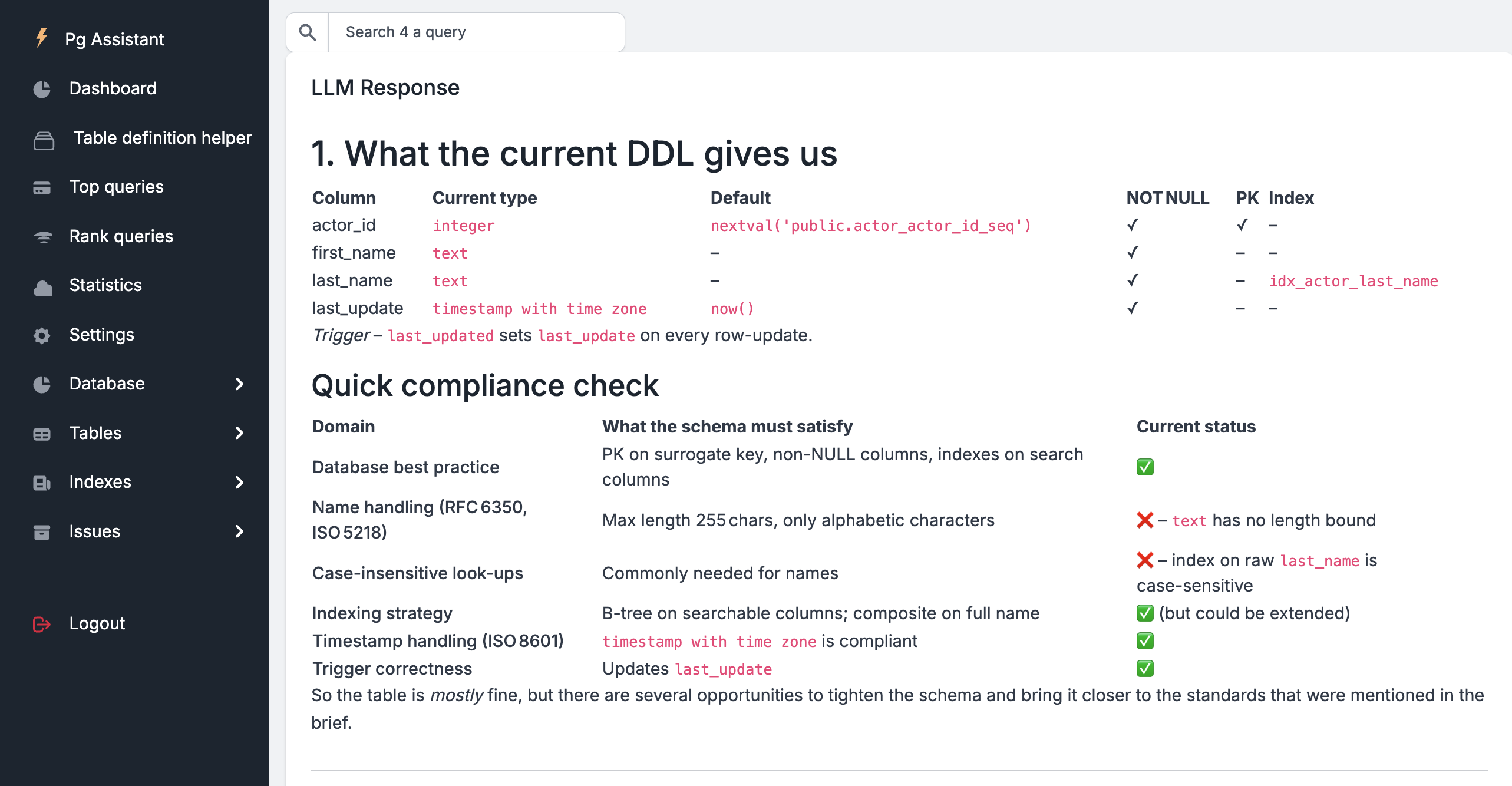

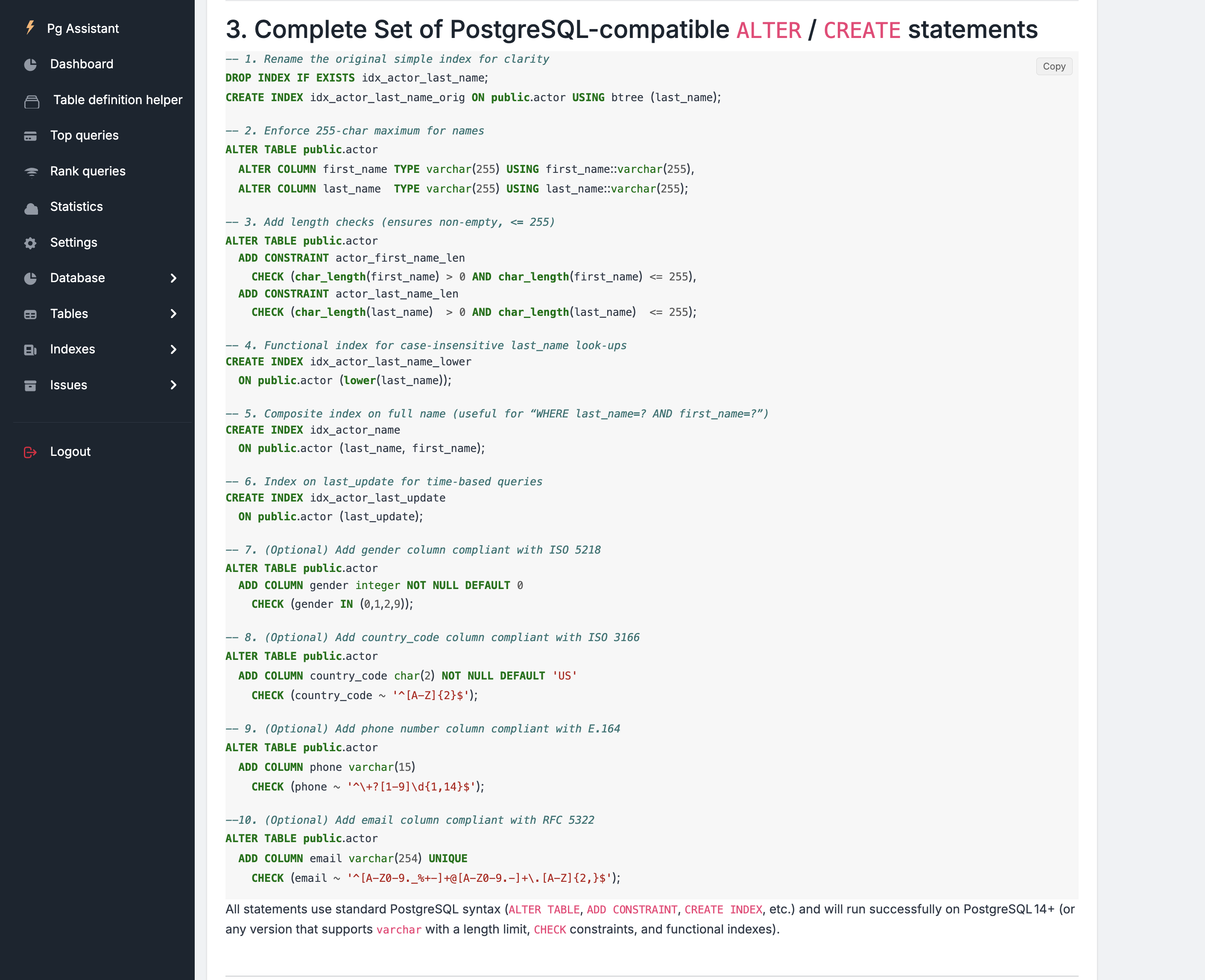
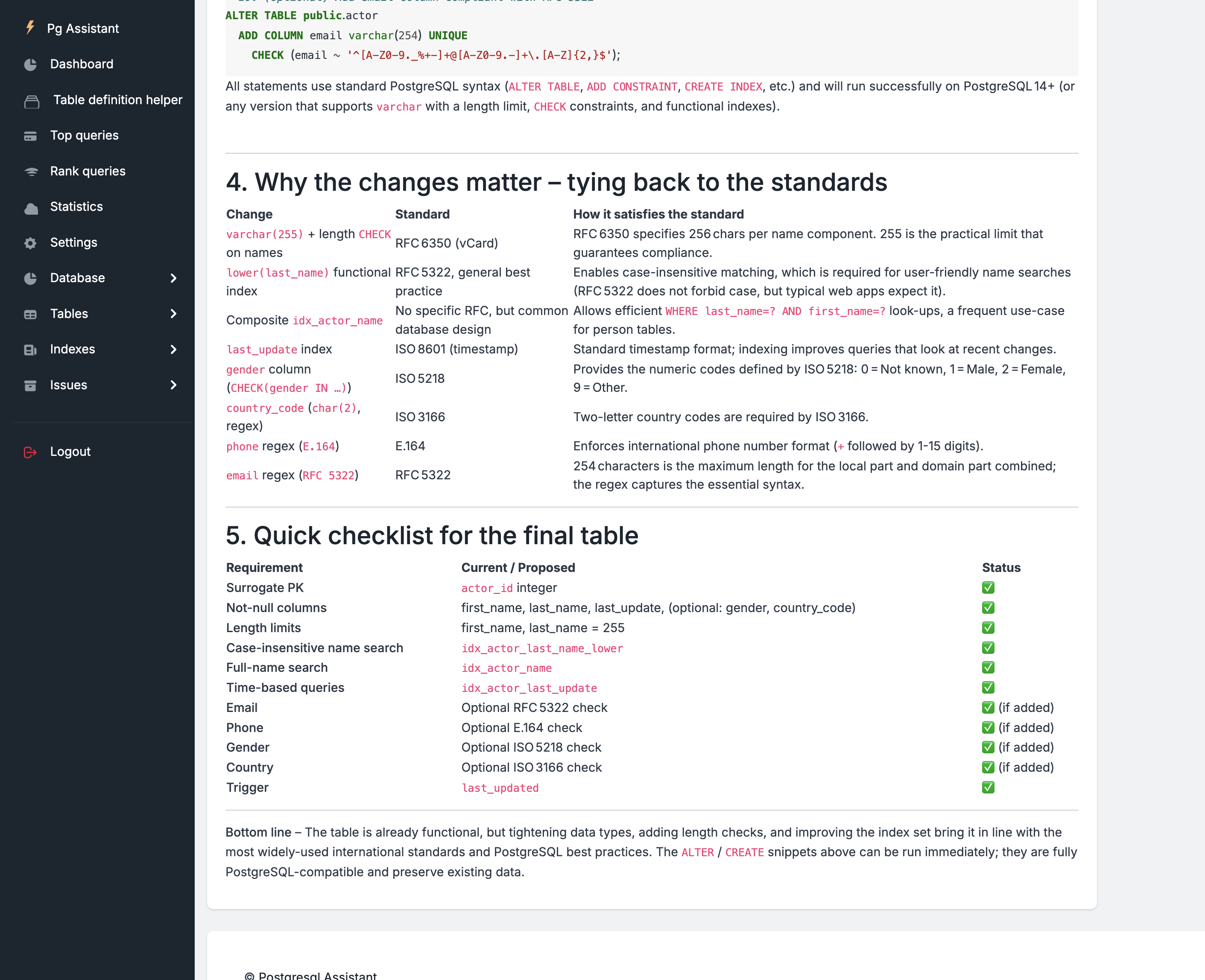
During the tests, Ollama utilized approximately 5% of the CPU, 95% of the GPU, and around 14 GB of memory.
Conclusions
The release of OpenAI’s new open-source model, gpt-oss, is genuinely impressive. Its response quality comes remarkably close to o4-mini, and it significantly outperforms all other open-source models I’ve tested so far.
That said, the model requires a substantial amount of memory — at least 24 GB — to run smoothly on a Mac. However, the investment is well worth it: running gpt-oss locally on a MacBook Pro M4 Pro with 24 GB RAM (approx. CHF 2,000) provides an outstanding developer experience.
As of now, gpt-oss:20b might be the best open-source companion for pgAssistant, both in terms of capabilities and local deployment flexibility and … price.