Detecting PostgreSQL optimization issues with deterministic analysis
For years, I kept seeing the same PostgreSQL problems in production:
- missing foreign key indexes
- stale statistics
- unused indexes
- datatype mismatches
- sequences approaching exhaustion
- postgres configuration
Most of these issues are not difficult to detect.
They already exist inside PostgreSQL catalogs, statistics, …
The difficult part is usually connecting the signals together and understanding their operational impact.
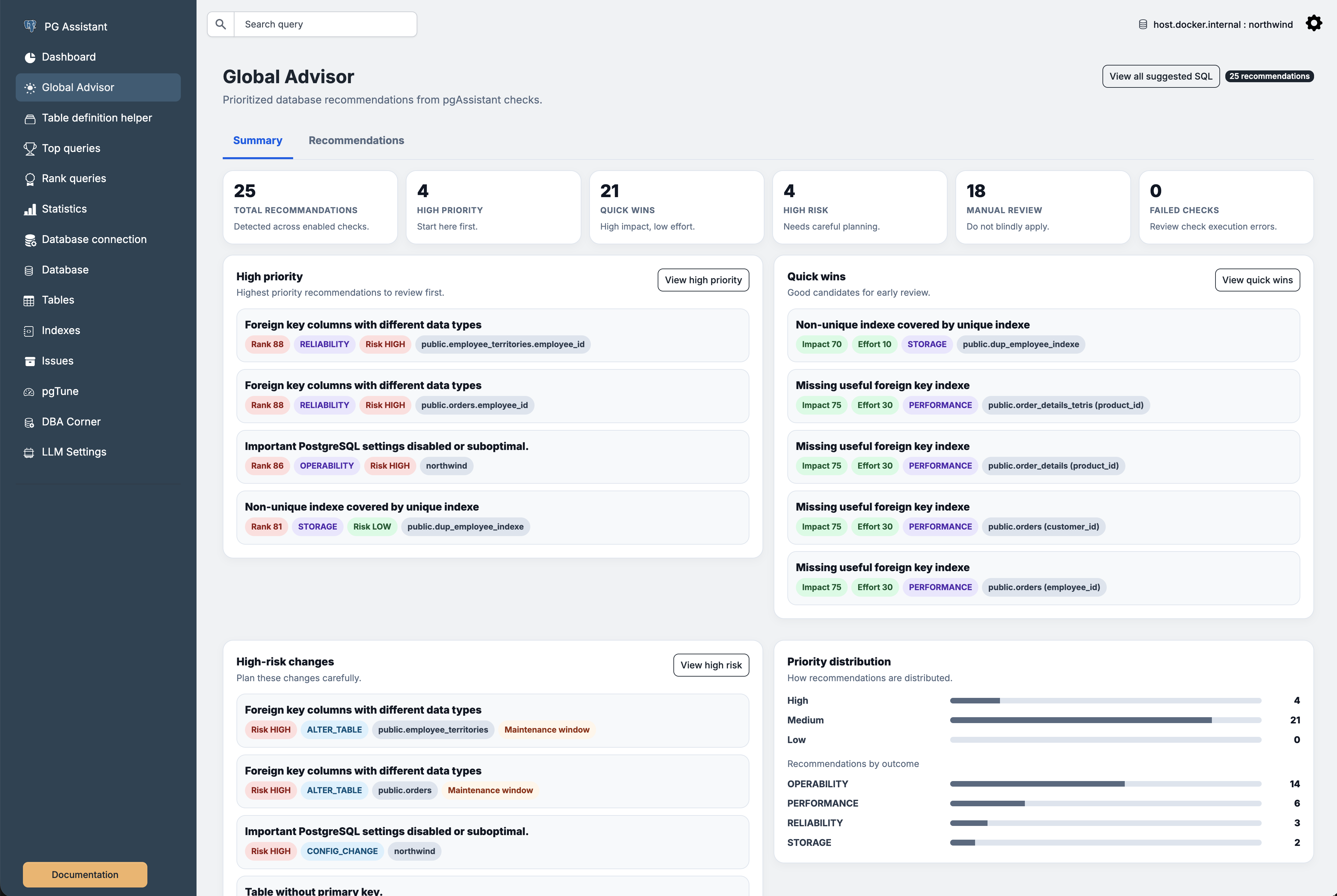
For the past months, I have been working on a deterministic PostgreSQL analysis approach inside pgAssistant 2.8.
This article shows several real optimization and schema issues automatically detected through PostgreSQL metadata analysis.
Why deterministic analysis?
The advisor intentionally avoids probabilistic reasoning for core diagnostics.
The findings come directly from PostgreSQL catalogs, statistics, and execution plans.
This means:
- same database → same findings
- reproducible diagnostics
- explainable results
The analysis currently relies on metadata such as:
pg_stat_user_tablespg_stat_user_indexespg_constraintpg_indexpg_settingspg_stats- etc. …
Examples of detected issues
Missing foreign key index causing DELETE slowdown
Situation
A production database had:
- ~40 tables
- many foreign keys
- slow
DELETEoperations on parent tables
Most SELECT queries were still relatively fast, making the root cause difficult to identify initially.
What was happening internally
Without an index on the foreign key column, PostgreSQL had to scan the child table during parent DELETE and UPDATE checks.
As the child table grew, lock duration and contention increased significantly.
Detected issue
The advisor detected:
- missing indexes on foreign keys
- high estimated operational impact
- low implementation effort
Suggested SQL:
CREATE INDEX CONCURRENTLY IF NOT EXISTS pga_idx_fk_orders_customer
ON public.orders(customer_id);
Result
After adding the index:
DELETElatency dropped significantly- lock duration became much shorter
- overall contention improved
In one environment, a DELETE operation dropped from several seconds to a few hundred milliseconds.
Datatype mismatch on foreign keys
Situation
A schema contained:
customers.id bigint
orders.customer_id integer
The relationship still worked correctly, but execution plans contained implicit casts.
Why this matters
Datatype mismatches on foreign keys often remain unnoticed for years.
Over time, they can create:
- planner inefficiencies
- inconsistent index usage
- migration complexity
- future overflow risks
Implicit casts can also prevent index usage in certain execution paths.
Detected issue
The advisor reported:
- foreign key datatype inconsistency
- possible planner inefficiencies
- potential index usage degradation
Suggested fix:
ALTER TABLE public.orders
ALTER COLUMN customer_id TYPE bigint
USING customer_id::bigint;
Result
After the change:
- execution plans became cleaner
- index usage became more predictable
This was not a dramatic performance gain, but it improved schema consistency and long-term maintainability.
Large unused indexes
Situation
One database had accumulated many historical indexes over several years.
Some indexes:
- were never scanned
- duplicated existing indexes
- consumed several GB of storage
Why this matters
Unused indexes are not free.
They increase:
- write amplification
- VACUUM overhead
- replication traffic
- maintenance complexity
In many systems, indexes survive much longer than the queries that originally required them.
Detected issue
The advisor identified:
- unused indexes
- duplicate indexes
- redundant non-unique indexes already covered by unique indexes
Suggested SQL:
DROP INDEX CONCURRENTLY IF EXISTS public.idx_old_customer_status;
Result
After validation and cleanup:
- storage usage decreased
- VACUUM became faster
- write overhead was reduced
- index maintenance became simpler
One cleanup operation removed more than 10 GB of unused indexes.
Tables with stale statistics
Situation
A large table (~100M rows) had unstable execution plans and unpredictable query latency.
The root cause was outdated planner statistics.
Why this matters
When planner statistics become inaccurate, PostgreSQL can start choosing inefficient execution plans.
In this case, the planner started preferring unstable nested loop plans instead of hash joins.
Detected issue
The advisor reported:
- high churn since last
ANALYZE - stale statistics
- outdated planner information
Suggested SQL:
ANALYZE public.events;
Result
After refreshing statistics:
- planner estimates improved
- execution plans stabilized
- nested loop misuse disappeared
Sequence approaching exhaustion
Situation
An application relied on an integer sequence approaching the 32-bit limit.
The issue had not yet been noticed operationally.
Why this matters
This is not directly a performance problem, but it is a production reliability problem.
Once the sequence limit is reached, inserts can start failing unexpectedly.
These issues are often discovered too late because sequences are rarely monitored proactively.
Detected issue
The advisor reported:
- sequence close to maximum value
- high severity warning
Current scope
The current deterministic checks include 15 recommandations like :
- missing FK indexes
- duplicate indexes
- unused indexes
- invalid indexes
- stale statistics
- table bloat estimation
- postgreSQL configuration problem
- datatype mismatch on foreign keys
- sequence exhaustion detection
Sample advisor detail
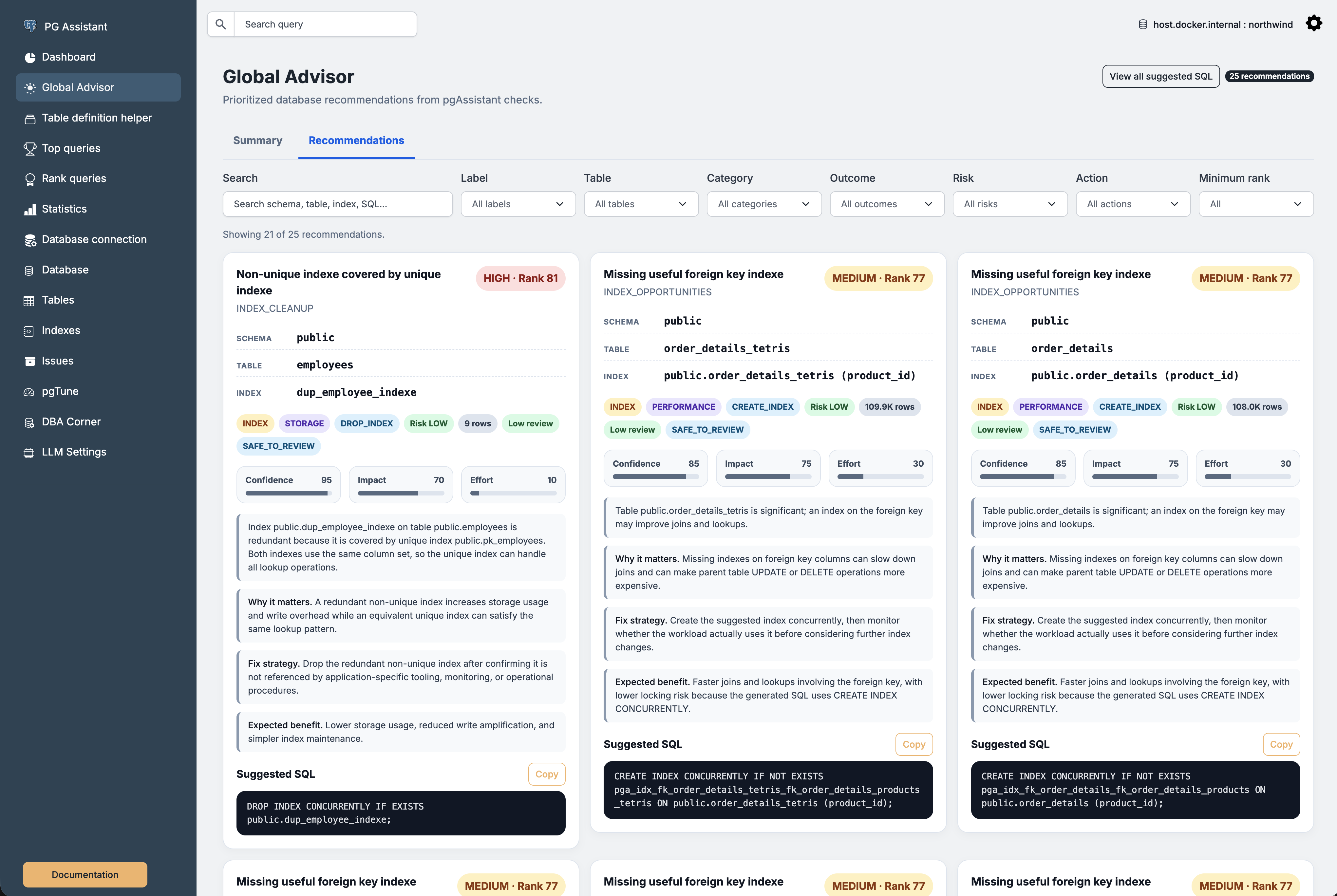
Closing thoughts
PostgreSQL already exposes a large amount of diagnostic information through catalogs, statistics, and execution plans.
Many production issues can be detected deterministically before they become incidents.
The goal of pgAssistant is simply to make these diagnostics easier to surface, prioritize, and understand.